Hello
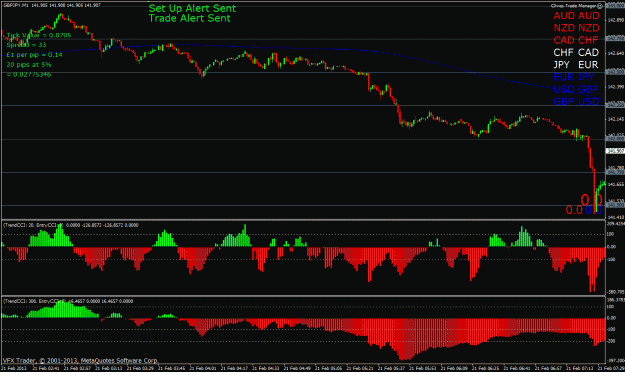
Lon-NY Day Trading Strategy was presented by Walker England
in FXCM Expo
I have attached a PDF file that explains the method
But better than that, there is a video of Walker England presents the strategy in detail. The video is here:
https://www.youtube.com/watch?v=lhO5ESAskTk
Does anyone know of this strategy? And have an opinion on it?
Would love to hear any comment you have on this strategy.
Lon-NY Day Trading Strategy was presented by Walker England
in FXCM Expo
I have attached a PDF file that explains the method
But better than that, there is a video of Walker England presents the strategy in detail. The video is here:
https://www.youtube.com/watch?v=lhO5ESAskTk
Does anyone know of this strategy? And have an opinion on it?
Would love to hear any comment you have on this strategy.
Attached File(s)