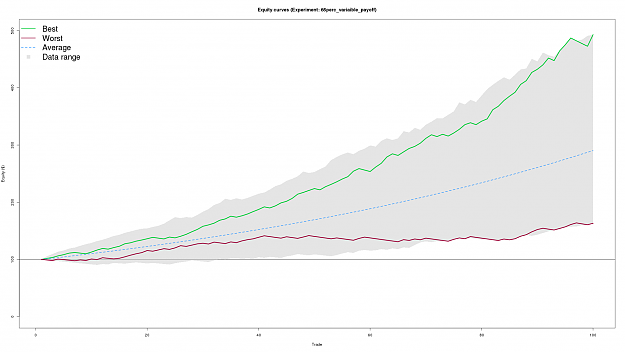
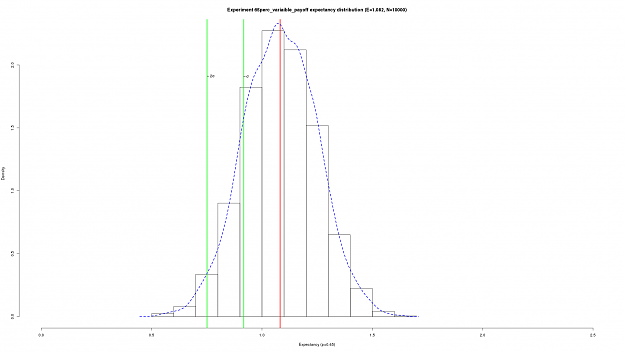
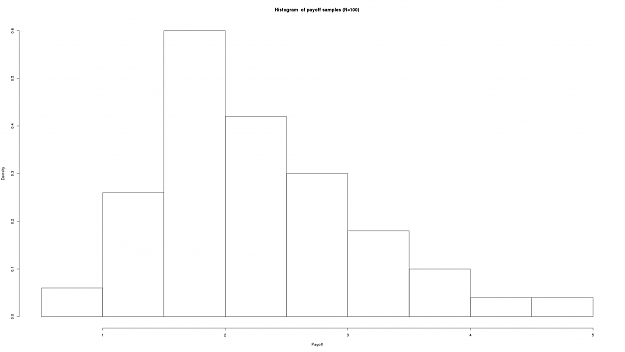
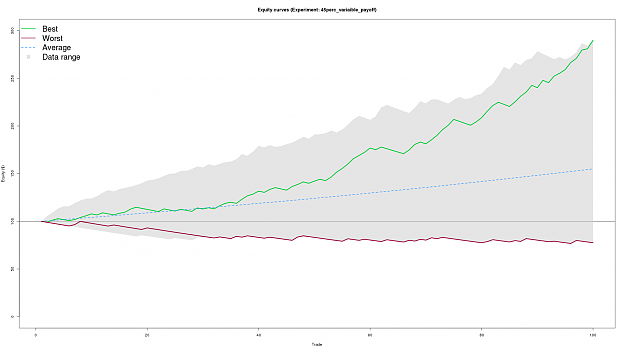
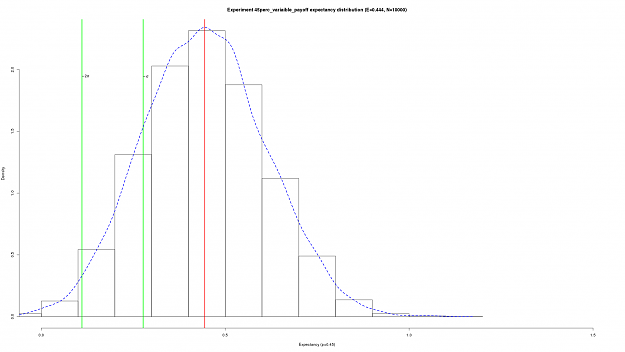
DislikedThanks FXEZ for putting up this thread and thanks guys for your valuable contributions. Very interesting stuff here that really helps seperate the wheat from the chaff. :-)Ignored
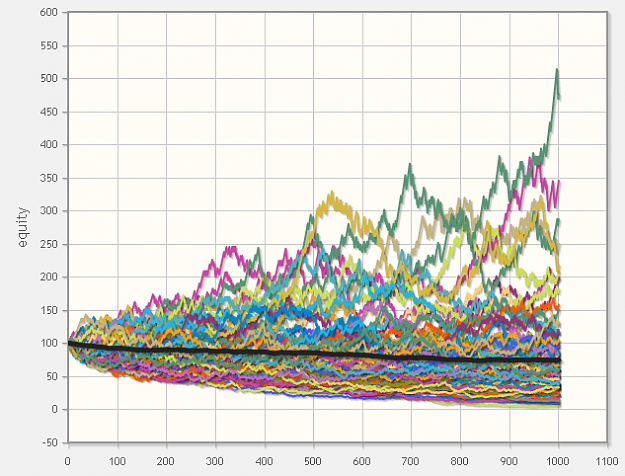
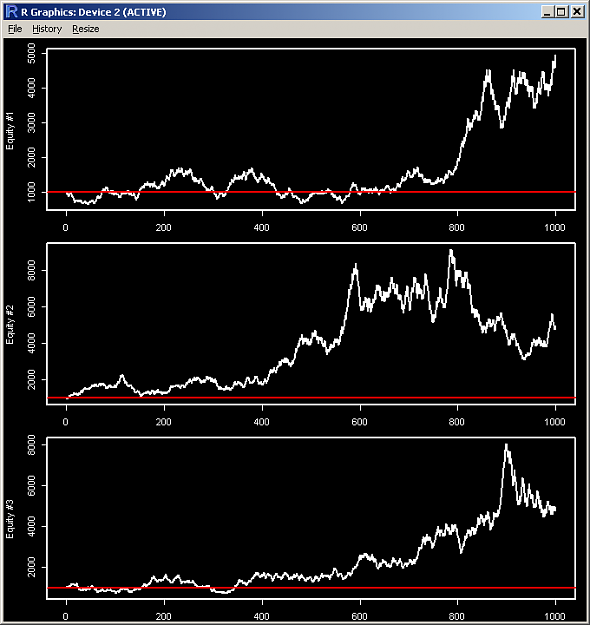
- #30
- Edited 5:03am Dec 29, 2016 1:34am | Edited 5:03am
- | Commercial User | Joined Apr 2013 | 4,366 Posts

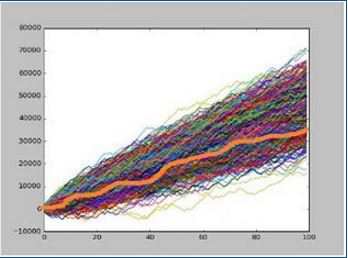
- #31
- Dec 29, 2016 8:56am Dec 29, 2016 8:56am
- Joined Aug 2011 | Status: Trader | 1,327 Posts
No greed. No fear. Just maths.
- #32
- Dec 29, 2016 9:17am Dec 29, 2016 9:17am
- Joined Aug 2011 | Status: Trader | 1,327 Posts
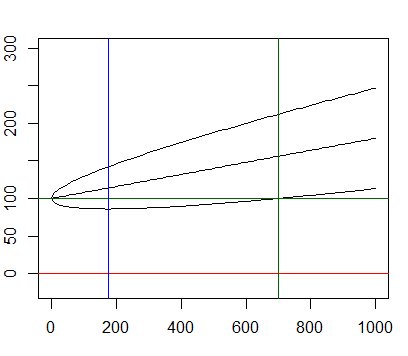
No greed. No fear. Just maths.
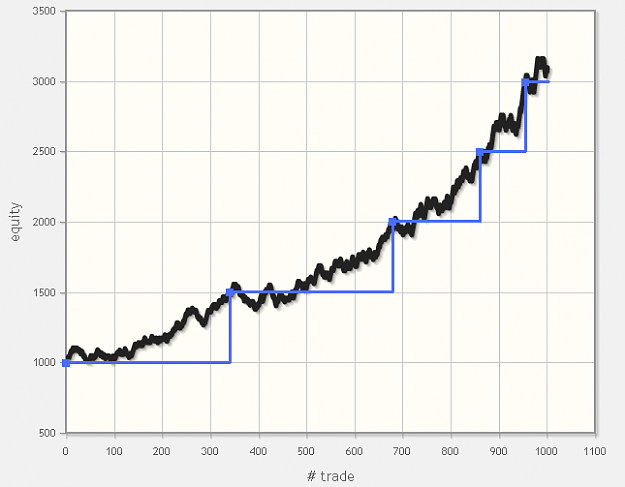
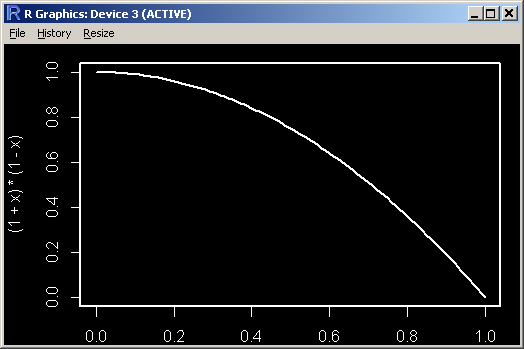

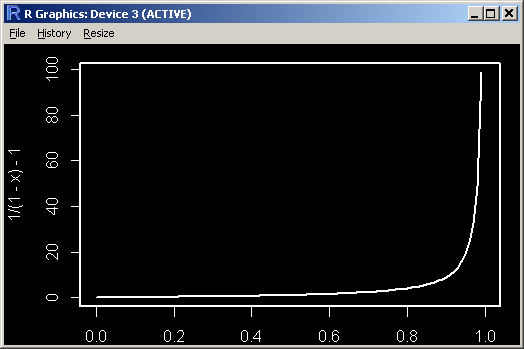
- #36
- Edited Dec 30, 2016 7:50am Dec 29, 2016 7:08pm | Edited Dec 30, 2016 7:50am
- | Commercial User | Joined Apr 2013 | 4,366 Posts