Hi all,
I dug up 15 years of daily prices on 15 currency pairs with the idea of looking at their returns distribution. I wanted to see if there was any chance that a trend-following approach could put us in the direction of a bigger amount of 2-sigma events (daily returns larger then 2 standard deviations). We know that financial time series are not normally distributed but rather have fat tails so I started doing some analysis. I ended up doing a lot more than just this. I'm not claiming this is all 100% accurate or that I have found a holy grail of any kind but I'd like to start some discussion. If anyone is interested and wants to replicate this stuff then perhaps we could falsify some of my results.
I added the historical quotes in attachment. They were extracted from Oanda. If we plot a histogram of the full sample of daily returns we can see that they have a high Kurtosis and definatly not normally distributed:
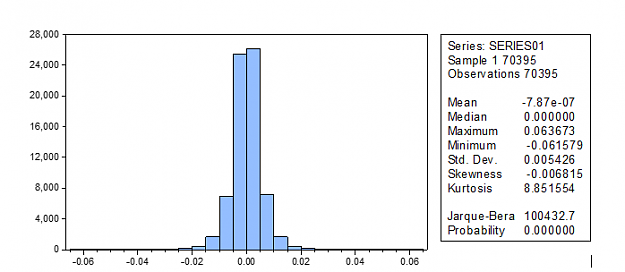
Sample maximum and minimum daily returns are 6.4% and -6.2% respectively. In attachment also the daily return histograms of all pairs individually.
So, I wanted to adopt a "trend-following" approach. I don't think there really is a good measurable way to define a trend. Clearly, I'm simplifying thing here. I construct three exponential moving averages (10,50,200) which corresponds to price being above/below the 10EMA on the MN, W1 and D1 charts together. Turns out that 58% of my observations qualify these criteria which is obviously a lot more than what I hear a lot that markets trend 30% of the time.
Plotting the histograms of daily returns when we are in 'trending up' conditions and when we are in 'trending down' conditions:

mean & median are positive and negative for trending up and trending down respectively. So under the 'trending' conditions, on average, we can expect more positive daily returns when trending up and more negative daily returns when trending down.
kurtosis for both remains high but the skewness I found pretty interesting. My very simple and crude rules seem to tilt the odds a bit in our favor?
Going further, it's obvious that trending up conditions still have large negative moves against us and trending down still have large positive daily returns against us. Let's have a look at the amount of large moves:

When trending up, 3% of daily returns are bigger then 2sigma and 2.6% are smaller then 2sigma. I can't really say much about statistically significant or anything but I found it intruiging. Same goes for trending down: 2.7% are more negative then 2sigma and 2.3% are more positive then 2sigma. Results for 3sigma events are qualitatively similar but clearly, less pronounced.
I went on and tried to see if, by any chance, we could mould this into some sort of system. Every day we check the close of the D1 candle and verify the conditions. If conditions are trending up we would go long and if conditions are trending down we would go short. A trend-following approach should have limited downside and unlimited upside. So I try to implement this: We would go with the direction of the trend every day as long as our conditions hold. This comes down to our 10EMA being our trailing stop. When the D1 closes below this we are no longer considered trending. In addition, we will apply a emergency SL. It's clear that being in an uptrend does not remove negative tail risk. So, every day we place a SL that is X*Sigma below the daily open. I realize that this goes against a very important saying: never make your SL bigger. But the idea is that the 10EMA is the SL and the X*Sigma is an emergency to limit our downside in case there is a large move against us.
So what should X be? We know that in trending conditions about 2.65% is going to be 2*Sigma against us and 0.70% is going to be 3*Sigma against us.
I multiple 'trending down' returns by -1 because we are short here. Add both trending up and trending down together for a total of 40428 observations. This should represent the "true" population because we obviously don't know what the true distribution is...
For X values of -0.005, -0.01 and -0.015 (1*Sigma, 2*Sigma and 3*Sigma) we bootstrap 2500 observations and run this bootstrap 100000 times. This means we randomize our array of 'trending' returns and randomly draw from this array 2500 times. 2500 is probably a bit too small to represent the true distribution of our sample returns but it corresponds to about 1 years worth of trading (40000 obs / 15 pairs) and 100000 tries should converge to the true values? (Not entirely sure about the properties of the estimators here)
We initialize our first row to 5000 which should represent our starting equity and we construct 100000 equity curves based on our bootstrapped returns (=randomly picked from our historical sample with replacement). Like I said, we limit our downside with our emergency stoploss so if the bootstrapped observations is below X*Sigma then we replace it by X*Sigma.
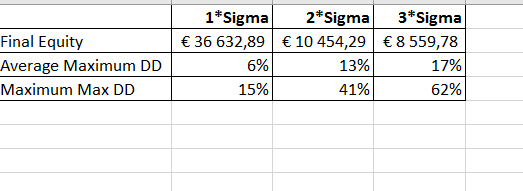
After running, we get a 2500x100000 matrix with equity curves per chosen multiple X. Calculate some basic stats per X:
For the 1*Sigma, I drew 200 randomly chosen equity curves:

Let's discuss. Do you think these results are realistic? Can you help me spot some mistakes? Any constructive feedback is welcome!
Best,
I dug up 15 years of daily prices on 15 currency pairs with the idea of looking at their returns distribution. I wanted to see if there was any chance that a trend-following approach could put us in the direction of a bigger amount of 2-sigma events (daily returns larger then 2 standard deviations). We know that financial time series are not normally distributed but rather have fat tails so I started doing some analysis. I ended up doing a lot more than just this. I'm not claiming this is all 100% accurate or that I have found a holy grail of any kind but I'd like to start some discussion. If anyone is interested and wants to replicate this stuff then perhaps we could falsify some of my results.
I added the historical quotes in attachment. They were extracted from Oanda. If we plot a histogram of the full sample of daily returns we can see that they have a high Kurtosis and definatly not normally distributed:
Attached Image (click to enlarge)
Sample maximum and minimum daily returns are 6.4% and -6.2% respectively. In attachment also the daily return histograms of all pairs individually.
So, I wanted to adopt a "trend-following" approach. I don't think there really is a good measurable way to define a trend. Clearly, I'm simplifying thing here. I construct three exponential moving averages (10,50,200) which corresponds to price being above/below the 10EMA on the MN, W1 and D1 charts together. Turns out that 58% of my observations qualify these criteria which is obviously a lot more than what I hear a lot that markets trend 30% of the time.
Plotting the histograms of daily returns when we are in 'trending up' conditions and when we are in 'trending down' conditions:
Attached Image (click to enlarge)
mean & median are positive and negative for trending up and trending down respectively. So under the 'trending' conditions, on average, we can expect more positive daily returns when trending up and more negative daily returns when trending down.
kurtosis for both remains high but the skewness I found pretty interesting. My very simple and crude rules seem to tilt the odds a bit in our favor?
Going further, it's obvious that trending up conditions still have large negative moves against us and trending down still have large positive daily returns against us. Let's have a look at the amount of large moves:
Attached Image (click to enlarge)
When trending up, 3% of daily returns are bigger then 2sigma and 2.6% are smaller then 2sigma. I can't really say much about statistically significant or anything but I found it intruiging. Same goes for trending down: 2.7% are more negative then 2sigma and 2.3% are more positive then 2sigma. Results for 3sigma events are qualitatively similar but clearly, less pronounced.
I went on and tried to see if, by any chance, we could mould this into some sort of system. Every day we check the close of the D1 candle and verify the conditions. If conditions are trending up we would go long and if conditions are trending down we would go short. A trend-following approach should have limited downside and unlimited upside. So I try to implement this: We would go with the direction of the trend every day as long as our conditions hold. This comes down to our 10EMA being our trailing stop. When the D1 closes below this we are no longer considered trending. In addition, we will apply a emergency SL. It's clear that being in an uptrend does not remove negative tail risk. So, every day we place a SL that is X*Sigma below the daily open. I realize that this goes against a very important saying: never make your SL bigger. But the idea is that the 10EMA is the SL and the X*Sigma is an emergency to limit our downside in case there is a large move against us.
So what should X be? We know that in trending conditions about 2.65% is going to be 2*Sigma against us and 0.70% is going to be 3*Sigma against us.
I multiple 'trending down' returns by -1 because we are short here. Add both trending up and trending down together for a total of 40428 observations. This should represent the "true" population because we obviously don't know what the true distribution is...
For X values of -0.005, -0.01 and -0.015 (1*Sigma, 2*Sigma and 3*Sigma) we bootstrap 2500 observations and run this bootstrap 100000 times. This means we randomize our array of 'trending' returns and randomly draw from this array 2500 times. 2500 is probably a bit too small to represent the true distribution of our sample returns but it corresponds to about 1 years worth of trading (40000 obs / 15 pairs) and 100000 tries should converge to the true values? (Not entirely sure about the properties of the estimators here)
We initialize our first row to 5000 which should represent our starting equity and we construct 100000 equity curves based on our bootstrapped returns (=randomly picked from our historical sample with replacement). Like I said, we limit our downside with our emergency stoploss so if the bootstrapped observations is below X*Sigma then we replace it by X*Sigma.
After running, we get a 2500x100000 matrix with equity curves per chosen multiple X. Calculate some basic stats per X:
Attached Image
For the 1*Sigma, I drew 200 randomly chosen equity curves:
Attached Image
Let's discuss. Do you think these results are realistic? Can you help me spot some mistakes? Any constructive feedback is welcome!
Best,
Attached File(s)

