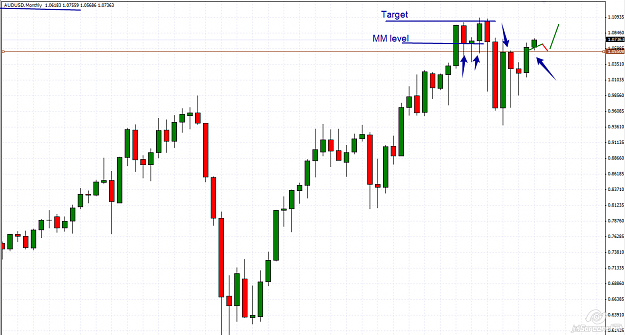
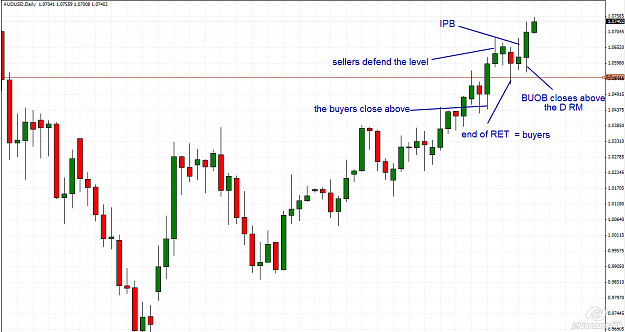
AUDUSD
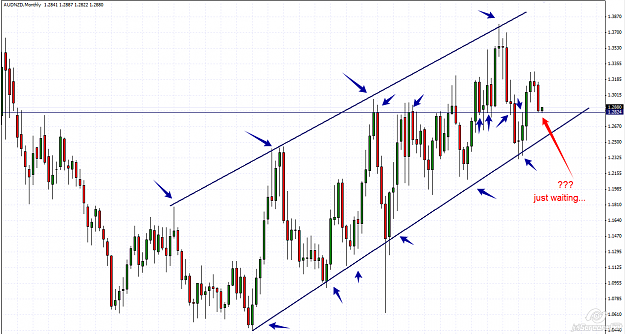
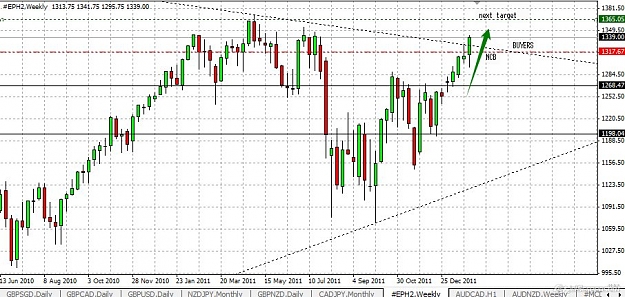
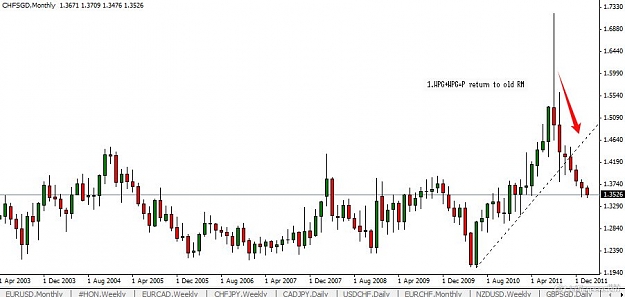
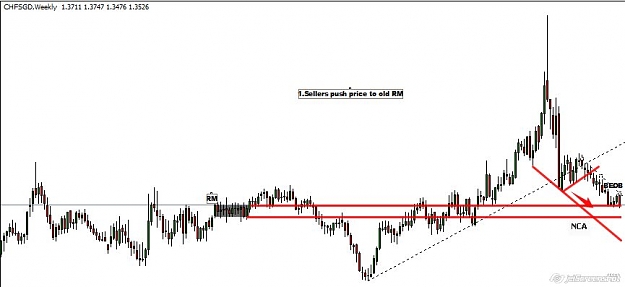
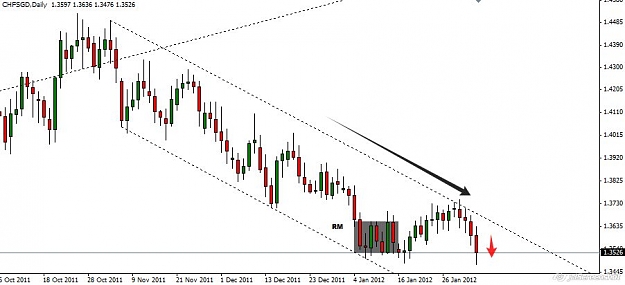
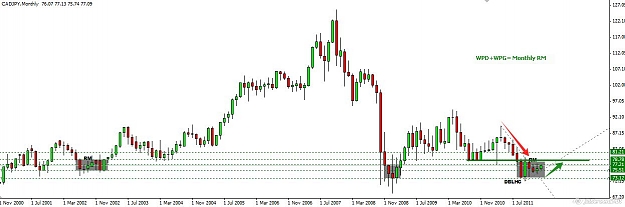
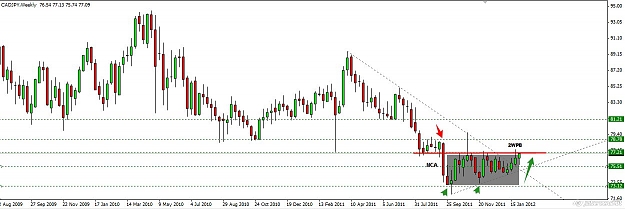
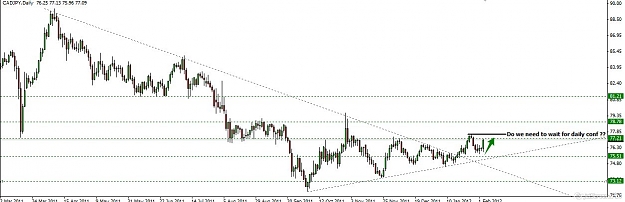
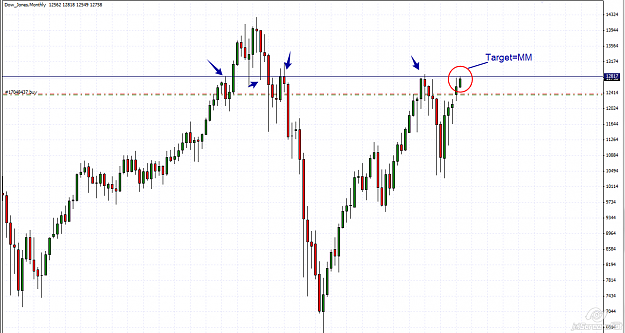
This pair is in a strong bullish trend and the M chart, gives us great information, meanwhile the D chart tells us something about the buyers .
This pair is in a strong bullish trend and the M chart, gives us great information, meanwhile the D chart tells us something about the buyers .
Attached Image(s) (click to enlarge)
Nothing personal,just business