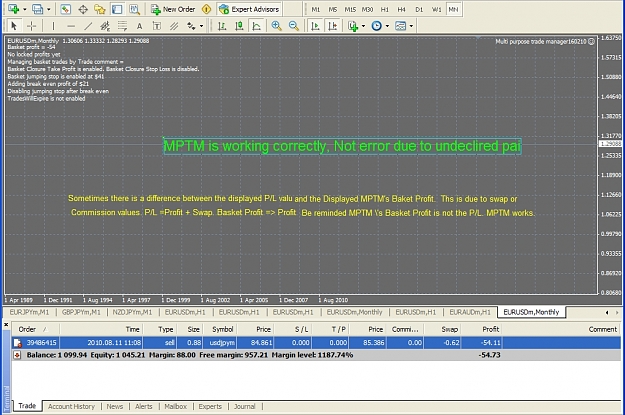
DislikedMy actual settings right now are -5000 pips to open which shows -50000 on-screen and actually works at -50. And my open percentage is set to 50% on screen shows 500% And works the same as the screen shows.Ignored
I have corrected this and the hedge my demo has just taken appears to be correct. The fix is in post 1.
This is an essential re-download for anybody using the new version who might/does use hedging.