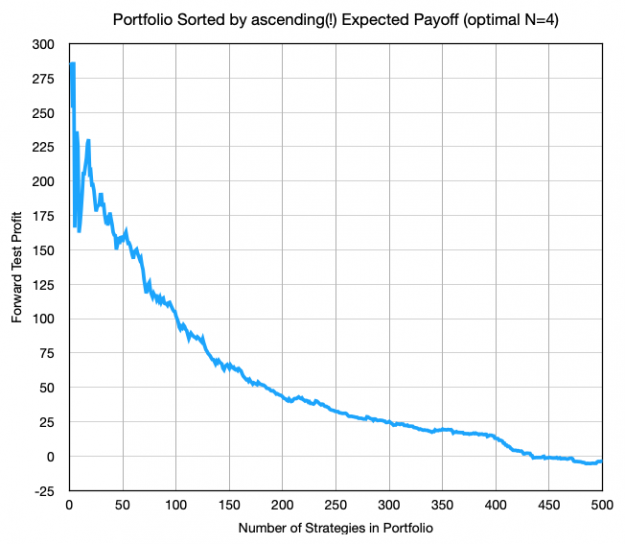
Trading is the hardest way to make easy money...
 Finding The Most Robust Parameters Using Optimization
Finding The Most Robust Parameters Using Optimization
- #26
- Dec 21, 2021 7:50am Dec 21, 2021 7:50am
- Joined Aug 2014 | Status: Trading | 2,163 Posts
Trading is the hardest way to make easy money...
- #33
- Dec 22, 2021 3:55am Dec 22, 2021 3:55am
- Joined Aug 2011 | Status: Trader | 1,327 Posts

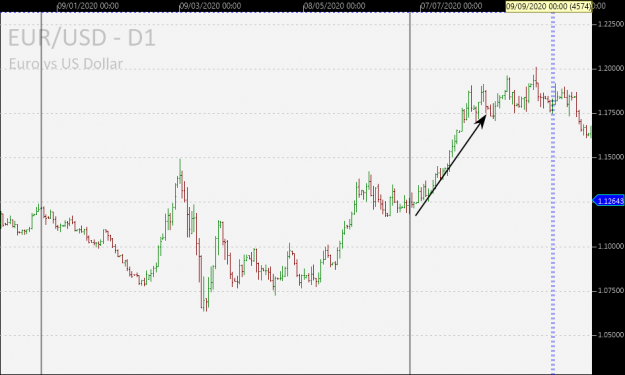
No greed. No fear. Just maths.
- #35
- Edited 12:30pm Dec 22, 2021 10:03am | Edited 12:30pm
- Joined Aug 2014 | Status: Trading | 2,163 Posts
Trading is the hardest way to make easy money...
- #36
- Edited 11:16am Dec 22, 2021 10:24am | Edited 11:16am
- Joined Dec 2017 | Status: Trader | 4,378 Posts