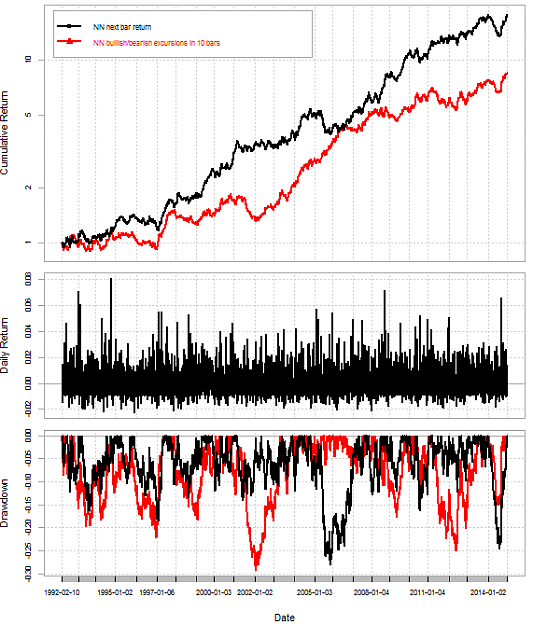
DislikedTo continue moving in the exploration of NN I am now going to show you the effect of making variations in the hidden and output functions as well as the number of optimization cycles per training for the NN using 100 examples to train (last three bar returns as inputs, next bar's return as target), remember that training of the models happens on every bar. The balance chart below shows you a comparison between FastSigmoid (FS), Linear (L) and Hyperbolic Tangent (HT) functions at different optimization cycle numbers. {image} There is a very large...Ignored
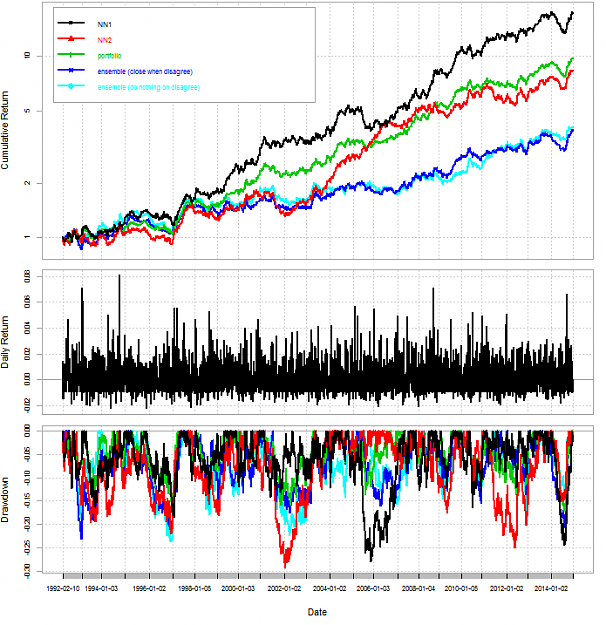
My idea: if we could find two NN algorithm with not so strict correlation than the ensemble could function better.
Reminds me if you had short position in two correlated pairs than it is almost the same as you had double in one pair (ok, slightly less loss).