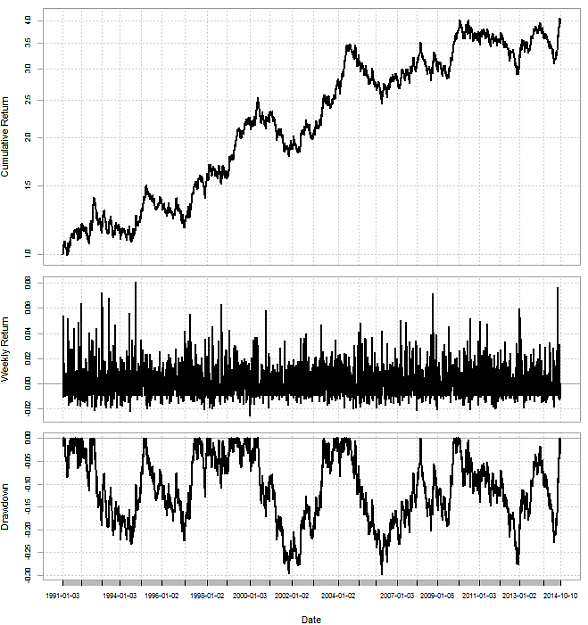
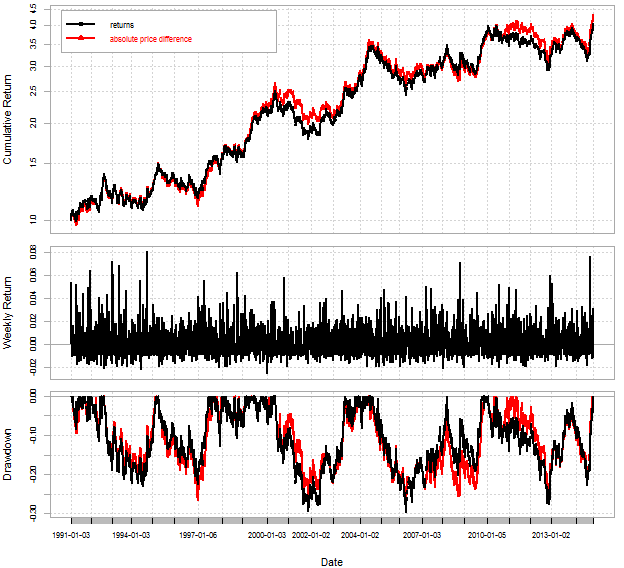
Disliked{quote} You train your K-NN or SVM using the past N examples, all of which have X bar directions as inputs and the target bar's direction as output. Using just the data you have posted you would build the examples: 0 0 => 0 0 0 => 1 0 1 => 0 0 1 => 1 1 0 => 0 1 0 => 1 1 1 => 0 1 1 => 1 Using examples like this you train the model on each bar and then you look for a prediction using the last data available. The last examples use 3 bars as input for the SVM and 4 bars as input for the K-NN. I use the open source shark...Ignored
I personally use java. Weka seems good and features a standalone GUI for quick and dirty testings.
There is no need for a full blown ML library anyway for a trivial k-NN. A VP-tree does the job.
I still don't understand. Even with the 4 bar directions as inputs you only get 16 combinations. In the past 200 days all of them appeared in E/U. Any query vector (the 4 previous days directions) will exactly match the center of one cell of this hypercube. Each cell contains two targets with different counts. If you request less than the number of elements in this cell the result depends on the order they will be retrieved from the data structure. This is not necessarily random enough to "shuffle" them and get a good result. If you request more neighbors than elements in the cell, the result depends even more on the implementation of the data structure. You may have each neighboring cells visited in order. Say you get (Up, Up) as your query vector. (Up, Down) and (Down, Up) are both 1 unit distant from (Up, Up). A recursive algorithm will visit the first one and get as many elements as needed before going to the next. For example almost all the elements of (Up, Down) could be returned while none of (Down, Up) would.
I see the kNN and SVM more useful when the training samples are more scattered in their area of influence.
No greed. No fear. Just maths.